It has been an enriching journey in human language technologies, working particularly acoustic and language models. This page outlines the main research topics and results.
Topics
Environmental Sound Events Detection

Abstract To detect the class, and start and end times of sound events in real world recordings is a challenging task. Current com- puter systems often show relatively high frame-wise accuracy but low event-wise accuracy. In this paper, we attempted to merge the gap by explicitly including sequential information to improve the performance of a state-of-the-art polyphonic sound event detection system. We propose to 1) use delayed predictions of event activities as additional input features that are fed back to the neural network; 2) build N-grams to model the co-occurrence probabilities of different events; 3) use se- quential loss to train neural networks. Our experiments on a corpus of real world recordings show that the N-grams could smooth the spiky output of a state-of-the-art neural network system, and improve both the frame-wise and the event-wise metrics.
An Investigation into LM Data Augmentation for Low-resourced ASR And KWS
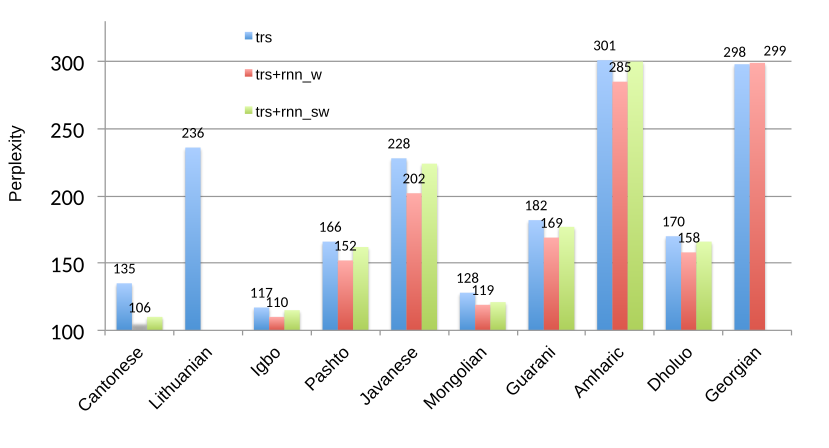
Abstract The linguistic regularities in the text data can be captured by recurrent neural networks (RNNs), which represent words by vectors, i.e., the input-layer weights. Taking advantage of the continuous-space word vectors, RNN based Language Models (LMs) have gained much momentum in the past few years. Compared with n-grams, the RNN-LMs provide better vocabulary coverage and reduce data sparsity. This is especially useful when dealing with out-of-vocabulary (OOV) words in ASR systems. I train various RNN-LMs using word and subword units, which then generate artificial text data to optimize the performance of LMs for ASR and keyword search (KWS) tasks. Word-based RNNs keep the same vocabulary so do not impact the OOV, whereas subword units can reduce the OOV rate. In particular, LMs including text data generated with RNNLMs improve ASR and KWS results on several low-resourced languages, such as Cantonese, Mongolian, Igbo, and Amharic.
Machine Translation Based Data Augmentation For Cantonese Keyword Spotting


Abstract In this work, the machine translation model is trained on a corpus of parallel Mandarin-Cantonese subtitles and used to translate a large set of Mandarin conversational telephone transcripts to Cantonese, which has limited resources. The translated transcripts are used to train a more robust language model for speech recognition and for keyword search in Cantonese conversational telephone speech. This method enables the keyword search system to detect 1.5 times more out-of-vocabulary words, and achieve 1.7% absolute improvement on actual term-weighted value.
An Adaptive Neural Control Scheme For Articulatory Synthesis of CV Sequences
Abstract Reproducing the smooth vocal tract trajectories is critical for high quality articulatory speech synthesis. This paper presents an adaptive neural control scheme for such a task using fuzzy logic and neural networks. The control scheme estimates motor commands from trajectories of flesh-points on selected articulators. These motor commands are then used to reproduce the trajectories of the underlying articulators in a 2nd order dynamical system. Initial experiments show that the control scheme is able to manipulate the mass-spring based elastic tract walls in a 2-dimensional articulatory synthesizer and to realize efficient speech motor control. The proposed controller achieves high accuracy during on-line tracking of the lips, the tongue, and the jaw in the simulation of consonant-vowel sequences. It also offers salient features such as generality and adaptability for future developments of control models in articulatory synthesis.
Articulatory Phonetic Features for Speech Recognition
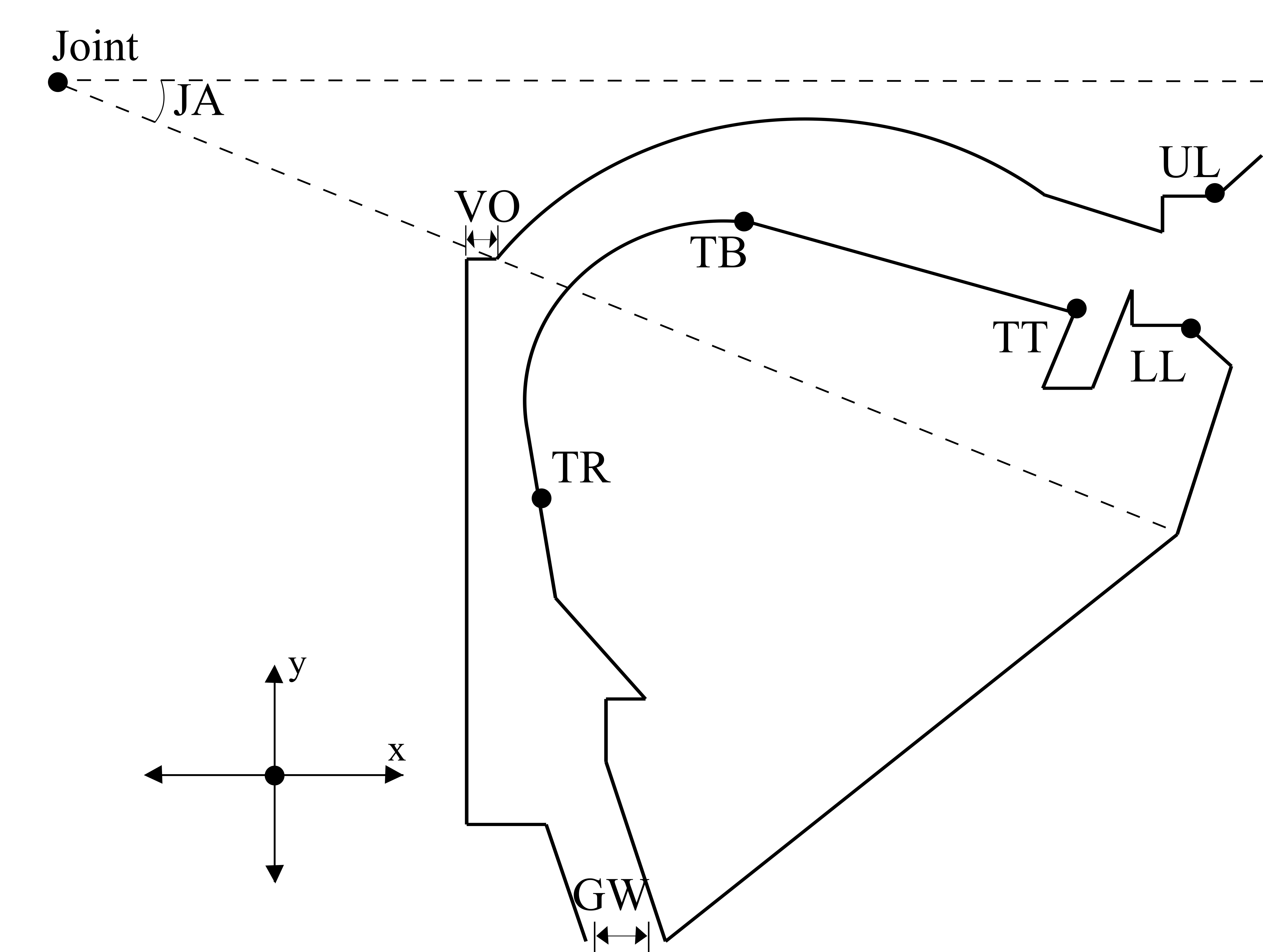
Abstract Acoustic-to-articulatory mapping is a challenging topic in speech research. Due to the nature of recording conditions, the articulatory data are less abundant than the acoustic data, thus they are usually retrieved or inverted from the latter. The main difficulty is that there exist multiple articulatory configurations that could produce the same acoustic output, i.e., the “many to one” problem. To alleviate this problem, I hypothesize that the muscular control signals are correlated with the articulatory trajectories and the acoustic features of human speech. I use the muscular control signal to constrain the number of articulatory configurations. I apply DNN to predict the articulatory trajectories from the acoustic features, e.g., MFCCs. Using a 2-hidden layer DNN, I obtain an average root mean square error below 1 mm on the EMA measures of selected articulator positions: upper/lower lips, lower incisor, tongue tip, tongue body, and tongue dorsum, on the multi-channel articulatory corpus, MOCHA-TIMIT. The retrieved articulatory trajectories and the acoustic features are then used together at the phonetic level to improve the ASR performance on TIMIT data.
Experiences
2023 - 2020 Post-doc: Multi-Modal Speech (Emotion) Recognition
2020 - 2023 Research Scientist: Toxic Text Classification with Transformers
2016 - 2020 Post-doc: Acoustic Events Analysis
2015 - 2016 Post-doc: Babel - Text Data Augmentation via Statistical Machine Translation and RNNLMs (Cantonese, English)
2012 - 2015 Post-doc: Speech Segmentation with Multi-View Features (Malay, English)
2008 - 2012 Doctoral: Automatic Speech Recognition with Articulatory Phonetic Features (English)
2004 - 2008 Bachelor: Digital Signal Processing: Audio/Image/Video; Information Theory; Literature Studies
Teaching
Spring/Fall 2009-2010
I was a teaching assistant for Engineering Mathematics. This was an undergrad-level course intended to introduce the basics of Mathematics to 2nd year University students.